Local Automatic Speech Recognition Utilizing Edge AI for Smart Assistant
Background
Automatic Speech Recognition (ASR) are more and more popular in smart home products. Nowadays, most of smart assistant are based on cloud model. It can be smart enough to answer user ‘s question.
However, there are still some concerns. Firstly, it require network connection to access the online model, which would be not reliable and higher latency if the network connection is unstable. Secondly, in some scenarios, e.g. in business meeting room, the smart assistant are not allowed to upload data to network because of data privacy. Thirdly, the user need to pay the model fee whether they use cloud model from Bydance or Baidu. But if they choose local Speech Recognition products, they just need to pay the hardware once and use it forever
Main Idea
Our main idea is to train a small model (or use existing model) which enable local speech recognition with edge AI (our mainstream product). We choose STM32MP2 (with 1.35 TOPS AI accelerator) as main processor and add KNX (a powerful standard in smart home/building automation), bluetooth or Wi-Fi interface (depend on product need) for system integration more easily.
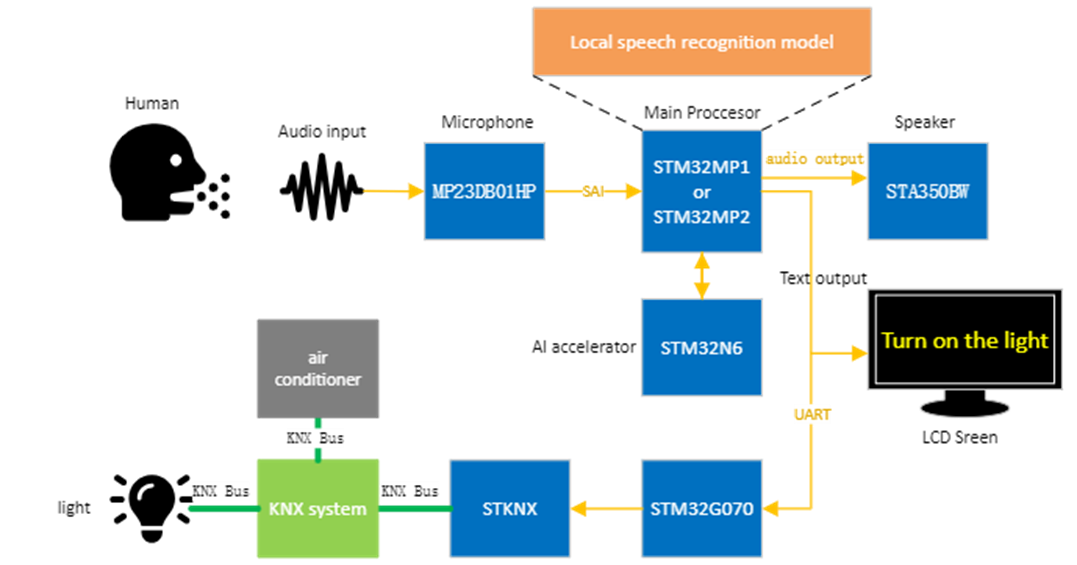
Challenge
This idea sounds so great. But why do we not seem those kind of product on the market? Here are two main challenges. Firstly, existing ASR model are too large to be implemented on embedded system. Common models are hundreds of the megabytes with large parameters and requires several TOPS calculation capability. Secondly, existing embedded system are neither too weak (hundreds of GOPS are high level) not too expensive to fit the product requirement.
What we are going to do is close the gap between the existing model and real application. We are going to build a demo using STM32MP2 to run a ASR system to show its capability.
We are semiconductor company, so our mission is to sell more microchip. Our demo can make our consumer understand more about our product and use more our product in their design.
Reference
Deep Learning Enabled Semantic Communications with Speech Recognition and Synthesis. paper, code
wenet-e2e/wenet: Production First and Production Ready End-to-End Speech Recognition Toolkit